Scraping formatted text from images
Image to Text conversion utilities
You can find here a small tokenization utility and examples of table extraction from images using Google Vision API. Google provides a good OCR to extract text from images but the output is not the best sometimes, in this repository I provide a simple postprocessing of the output in order to make it easier to use the API output.
Motivation
Google OCR provides a text output which might not have the expected format, if that’s the case it also provides a JSON output with information about the position of each recognized entity. The problem is that this data is not so well structured for some tasks, extracting tokens (Series of characters without spaces between each other) is not so easy with this JSON since it doesn’t provides directly this information. The goal of this is to provide a way to postprocess this data into something more maneagable, so it’s more appropiate for text processing tasks like extracting full lines of text or filtering words.
In order to do this a postprocessing code is provided at src/image2tokens.py. This is applied in order to extract tokens and then even more abstract concepts like text lines or table columns.
Demo
Sample Input
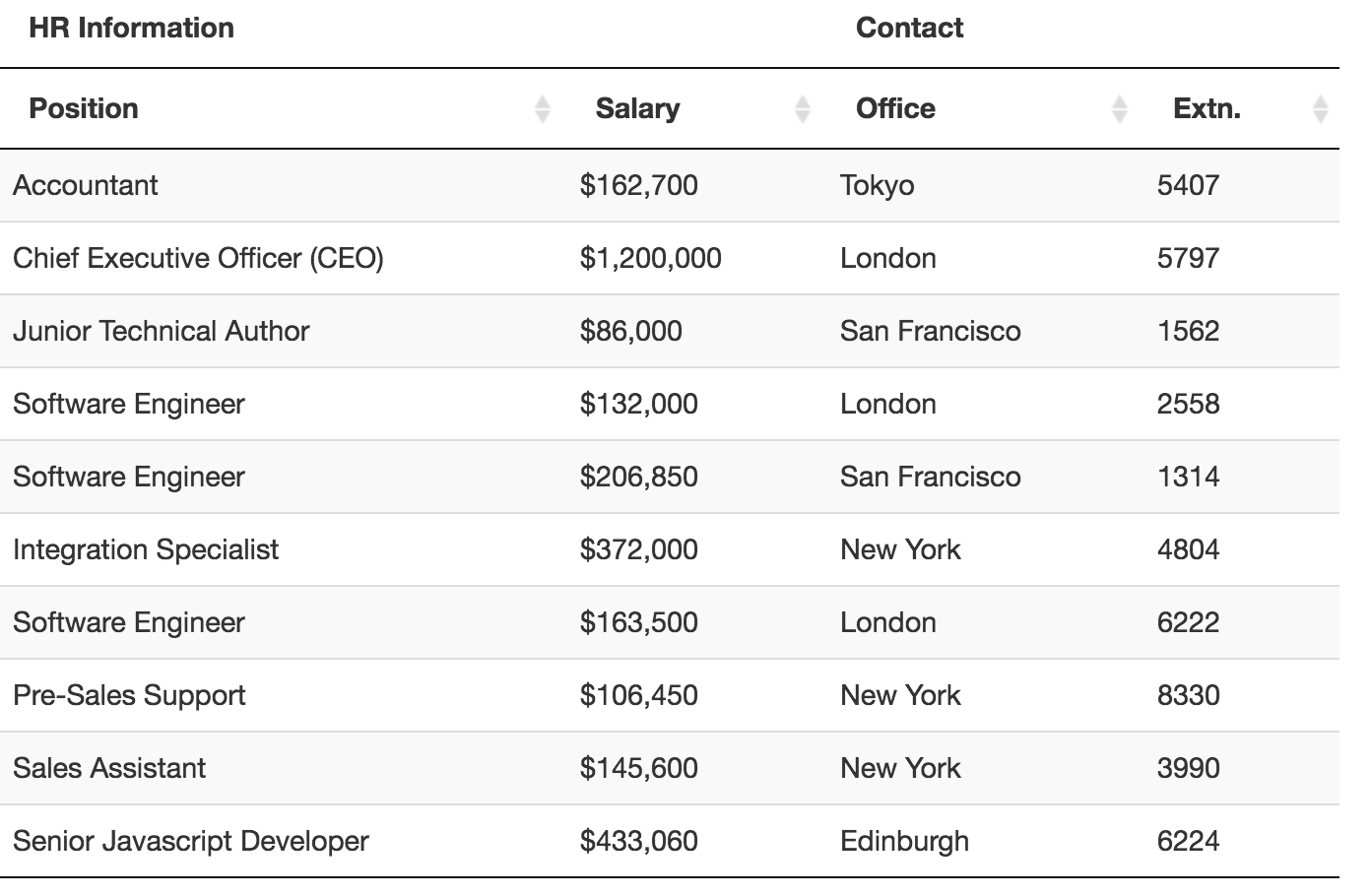
Sample Output
1 | HR Information Contact |